Как реализовать стек в Python
Возможно вы что то слышали о стеках и задавались вопросом, что это такое? У вас есть общее представление об этом, но вам интересно, как реализовать стек в Python? Тогда вы пришли в нужное место!
В этой статье вы узнаете:
- Как распознать, когда стек является хорошим выбором структуры данных
- Как решить, какая реализация стека лучше для вашей программы
- Какие дополнительные соображения следует учитывать при использовании стеков в многопоточной или многопроцессорной среде
Это руководство предназначено для питонистов, которые хорошо разбираются в сценариях, знают, что такое списки и как их использовать, и интересуются, как реализовать стек в Python.
Что такое стек?
Стек – это структура данных, в которой элементы хранятся в порядке поступления. Его еще часто называют LIFO (Last-In/First-Out). Это отличается его от очереди, в которой элементы хранятся в порядке «первым пришел / первым обслужен» (FIFO).
Вероятно, проще всего понять стек, если вы представите сценарий использования, с которым вы, вероятно, знакомы: функция отмены (Undo) в вашем редакторе.
Давайте представим, что вы редактируете вашу программу на Python. Сначала вы добавляете новую функцию. Это добавляет новый элемент в стек отмены:
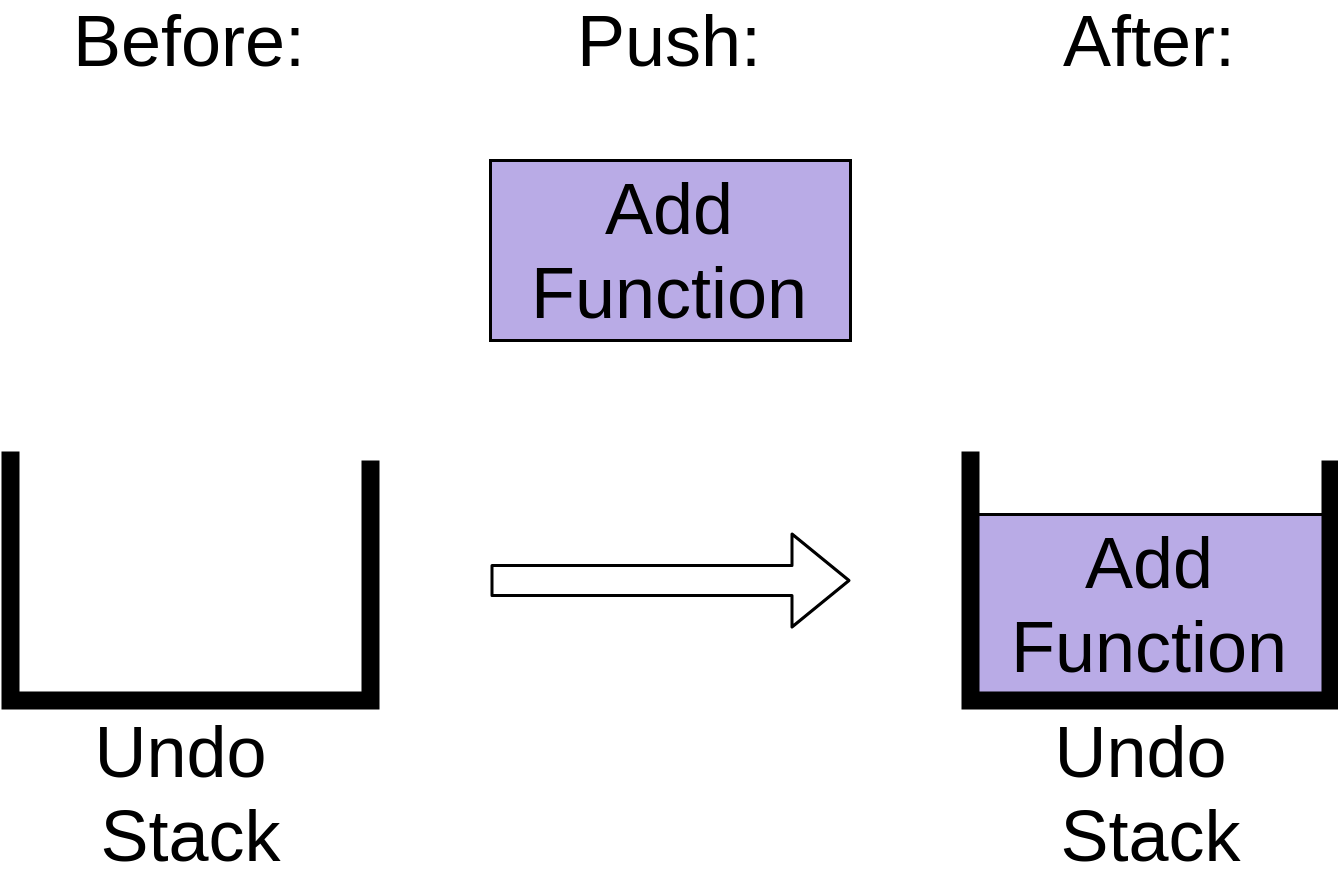
Вы можете видеть, что в стеке теперь есть операция Add Function. После добавления функции вы удаляете слово из комментария. Это также добавляется в стек отмены:
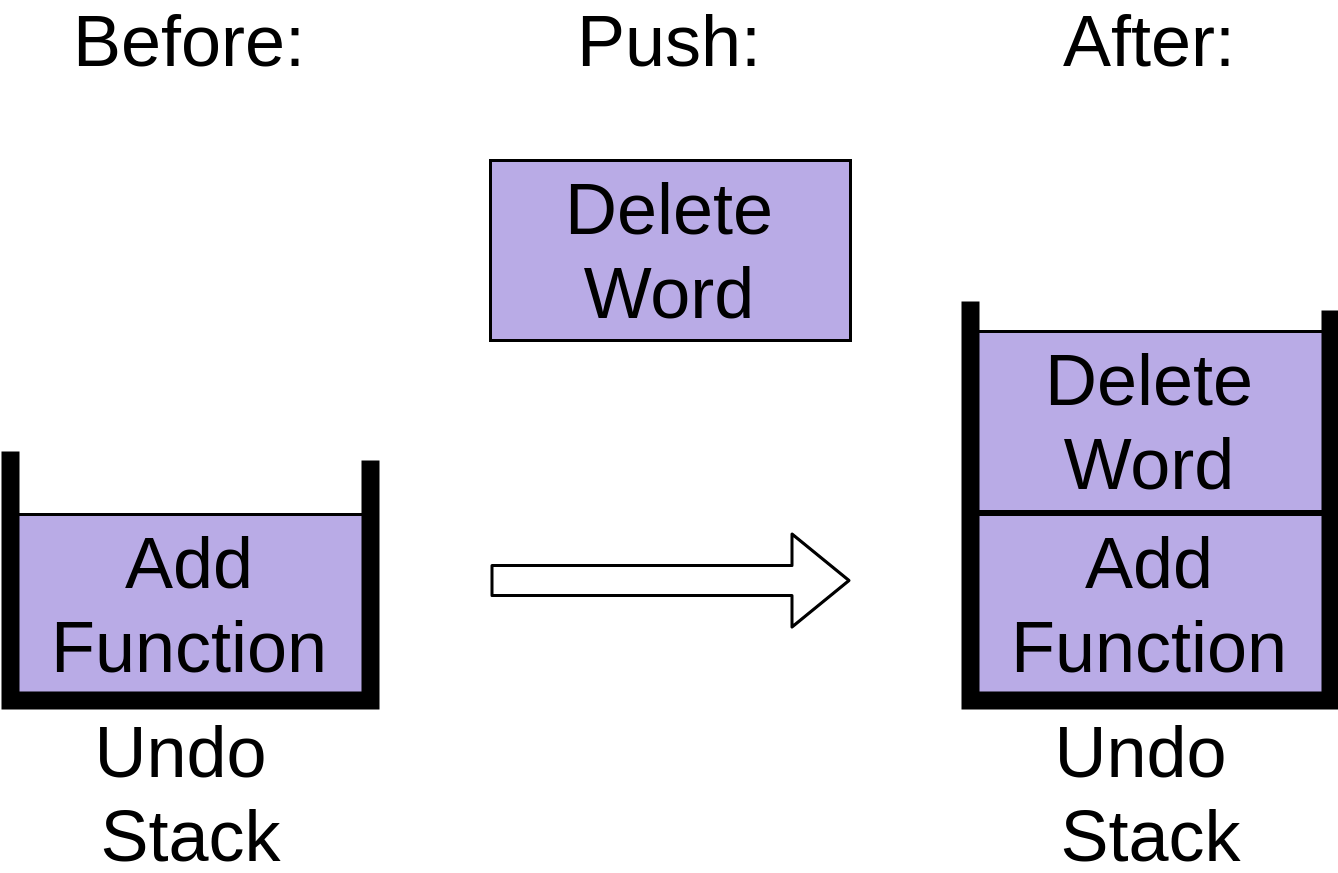
Обратите внимание, как элемент «Delete Word» помещается на вершину стека. Наконец, вы делаете отступ для комментария, чтобы он выстроился правильно:
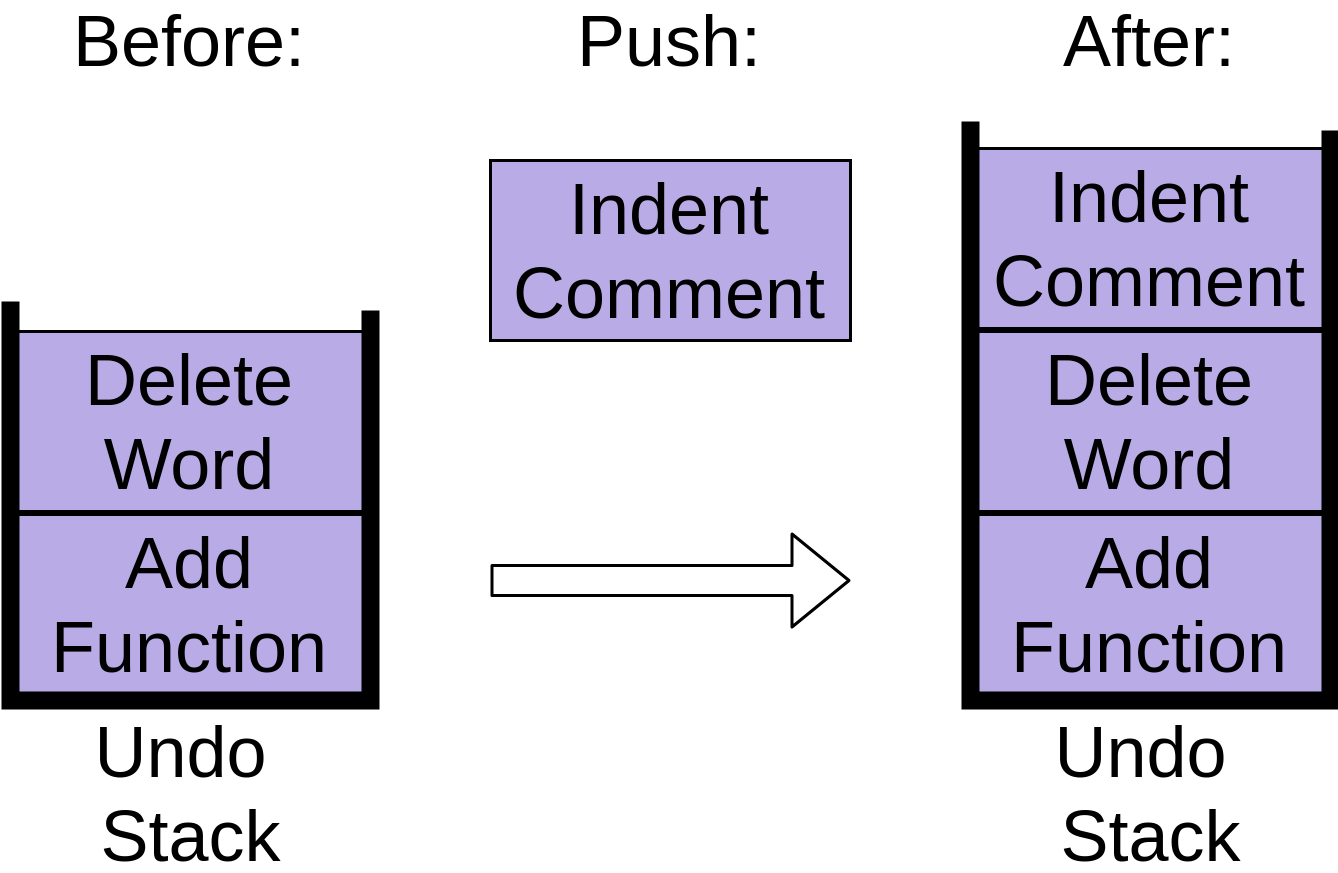
Вы можете видеть, что каждая из этих команд хранится в стеке отмены, а каждая новая команда помещается сверху. Когда вы работаете со стеком, добавление новых элементов, подобных этому, называется push.
Теперь вы решили отменить все три изменения, поэтому вы нажимаете команду отмены. Далее берется элемент в верхней части стека, который делал отступ для комментария, и удаляется из стека:
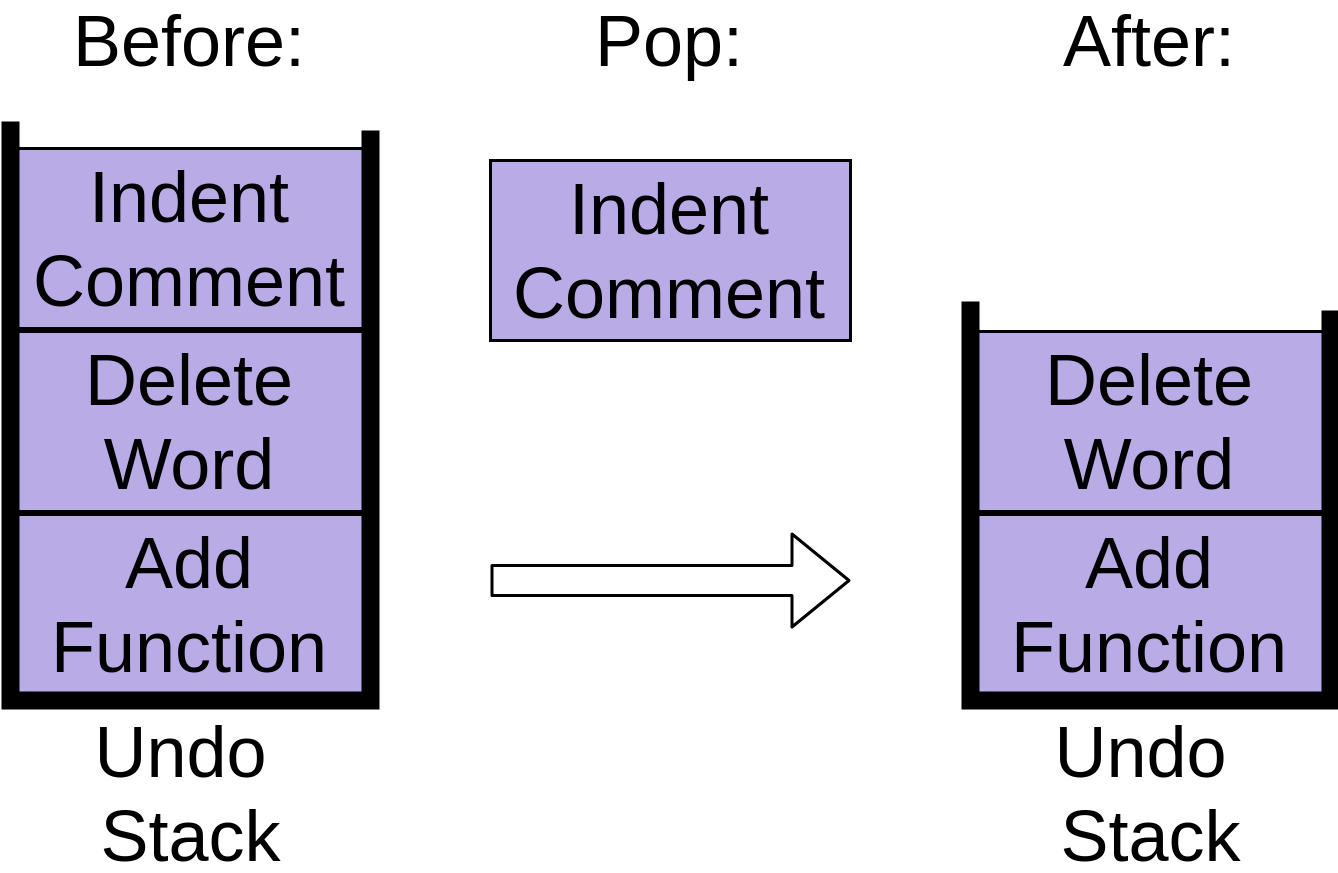
Ваш редактор отменяет отступ, а стек отмены теперь содержит два элемента. Эта операция противоположна push и обычно называется pop.
Когда вы снова нажмете кнопку «Отменить», из стека выскочит следующий предмет:
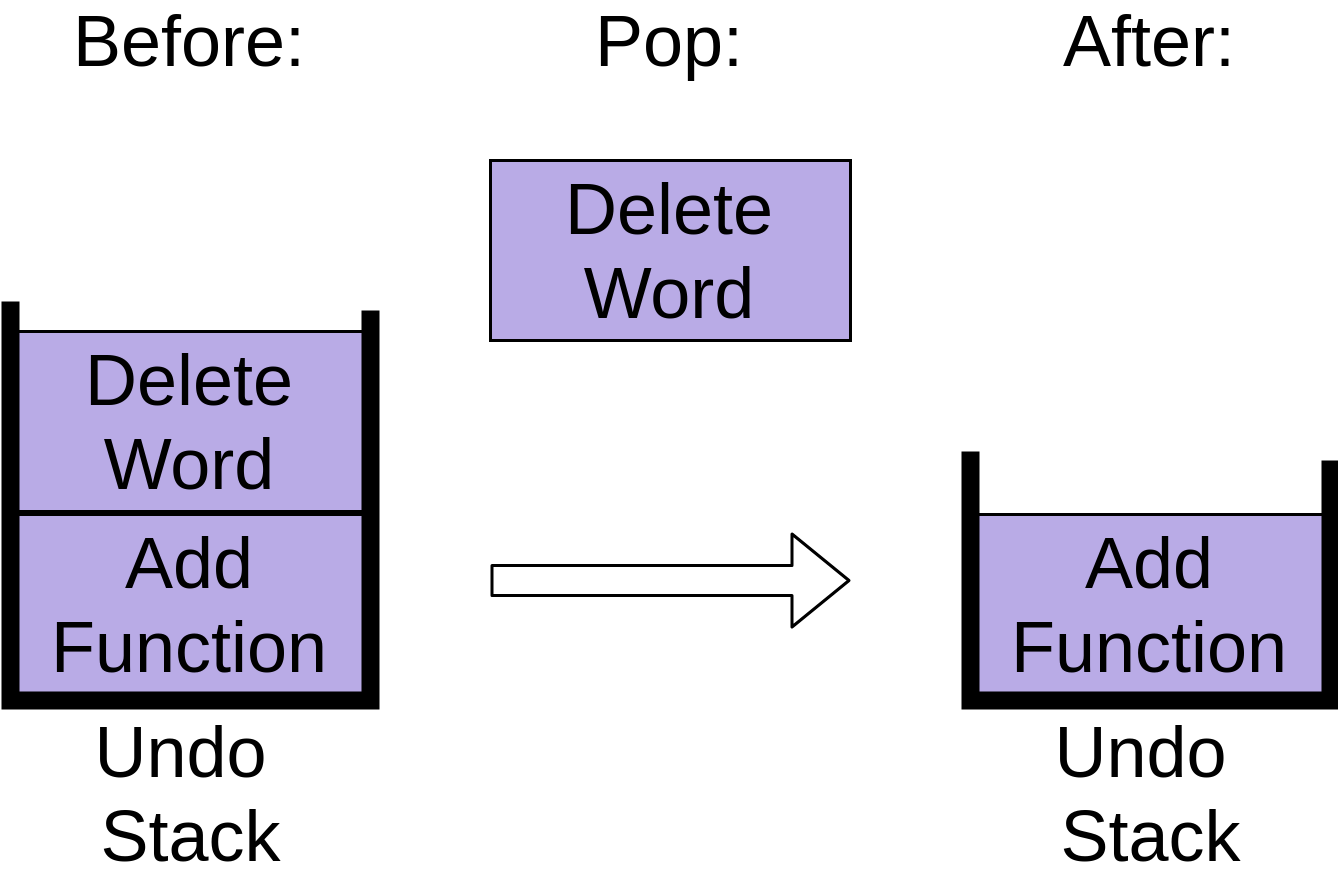
Удалится элемент «Delete Word», оставляя только одну операцию в стеке.
Наконец, если вы нажмете Отменить в третий раз, то последний элемент будет вытолкнут из стека:
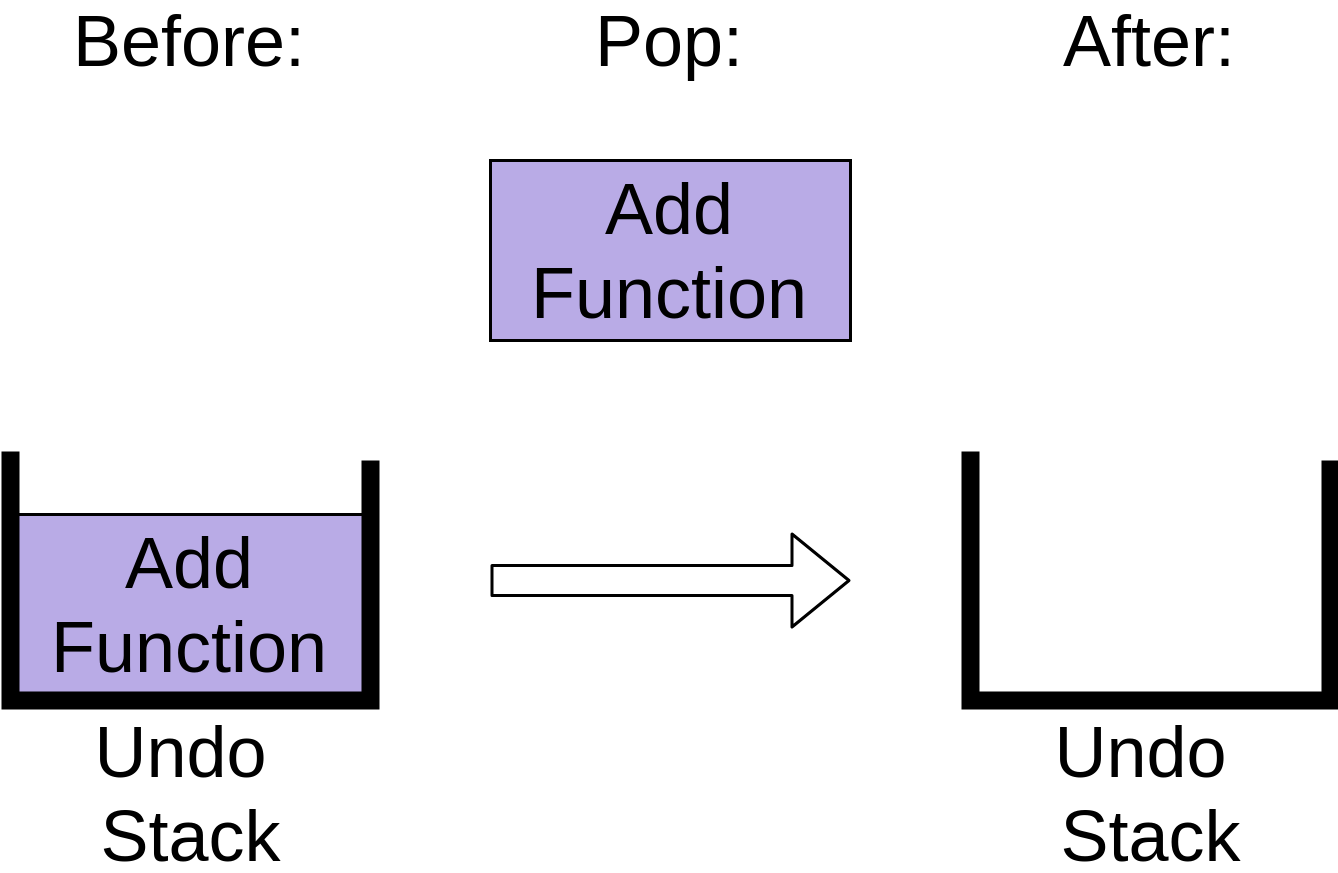
Стек отмены теперь пуст. Повторное нажатие кнопки «Отменить» после этого не даст никакого эффекта, поскольку ваш стек отмены пуст, по крайней мере, в большинстве редакторов. Вы увидите, что произойдет, когда вы вызовете .pop() для пустого стека в описании реализации ниже.
Реализация стека в Python
Есть несколько вариантов, когда вы реализуете стек в Python. Эта статья не охватывает все из них, только основные, которые будут соответствовать почти всем вашим потребностям. Мы сосредоточимся на использовании структур данных, которые являются частью библиотеки Python, и не используют сторонних пакетов.
Мы посмотрим на следующие реализации стека:
listcollections.dequequeue.LifoQueue
Использование list для создания стека
Встроенная структура list, которую вы, вероятно, часто используете в своих программах, может использоваться и в качестве стека. Вместо .push() можно использовать .append() для добавления новых элементов в верхнюю часть стека, в то время как .pop() удаляет элементы в порядке LIFO:
>>> myStack = []
>>> myStack.append('a')
>>> myStack.append('b')
>>> myStack.append('c')
>>> myStack
['a', 'b', 'c']
>>> myStack.pop()
'c'
>>> myStack.pop()
'b'
>>> myStack.pop()
'a'
>>> myStack.pop()
Traceback (most recent call last):
File "<console>", line 1, in <module>
IndexError: pop from empty list
В последней команде вы можете видеть, что список вызовет IndexError, если вы вызовете .pop() в пустом стеке.
list имеет преимущество, в том что он прост и вы знаете, как он работает и, вероятно, уже использовали его в своих программах.
К сожалению, у list есть несколько недостатков по сравнению с другими структурами данных. Самая большая проблема заключается в том, что он может столкнуться с проблемами по скорости по мере увеличение размера данных. Элементы в списке хранятся с целью обеспечения быстрого доступа к случайным элементам в списке. На низком уровне это означает, что элементы хранятся рядом друг с другом в памяти.
Если ваш стек становится больше, чем блок памяти, в котором он находится на данный момент, то Python должен сделать некоторое дополнительное выделения памяти. Это может привести к тому, что некоторые вызовы .append() будут занимать намного больше времени, чем другие.
Есть и менее серьезная проблема. Если вы используете .insert() для добавления элемента в ваш стек в позиции, отличной от конца, это может занять гораздо больше времени. Однако обычно это не то, что вы делаете со стеком.
Следующая структура данных поможет вам обойти проблему перераспределения памяти.
Использование collection.deque для создания стека
Модуль collection содержит deque, который полезен для создания стеков. deque переводиться как «колода» и означает «двусторонняя очередь».
Вы можете использовать те же методы для deque, которые мы видели выше для list, .append() и .pop():
>>> from collections import deque
>>> myStack = deque()
>>> myStack.append('a')
>>> myStack.append('b')
>>> myStack.append('c')
>>> myStack
deque(['a', 'b', 'c'])
>>> myStack.pop()
'c'
>>> myStack.pop()
'b'
>>> myStack.pop()
'a'
>>> myStack.pop()
Traceback (most recent call last):
File "<console>", line 1, in <module>
IndexError: pop from an empty deque
Это выглядит почти идентично приведенному выше примеру со списком. В этот момент вам может быть интересно, почему разработчики ядра Python создают две структуры данных, которые выглядят одинаково.
Зачем нужен deque если есть list?
Как вы видели в обсуждении списка выше, он был построен на блоках непрерывной памяти, что означает, что элементы в списке хранятся рядом друг с другом:
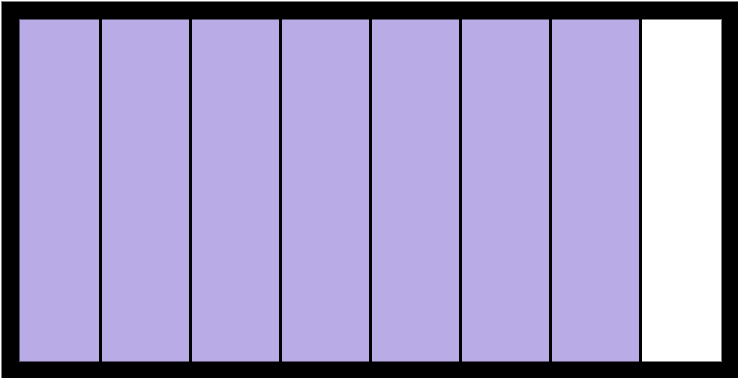
Это отлично работает для нескольких операций, таких как индексация в списке. Так получение элемента по индексу myList[3] работает быстро, так как Python точно знает, где искать в памяти. Эта схема памяти также позволяет хорошо работать со срезами списков.
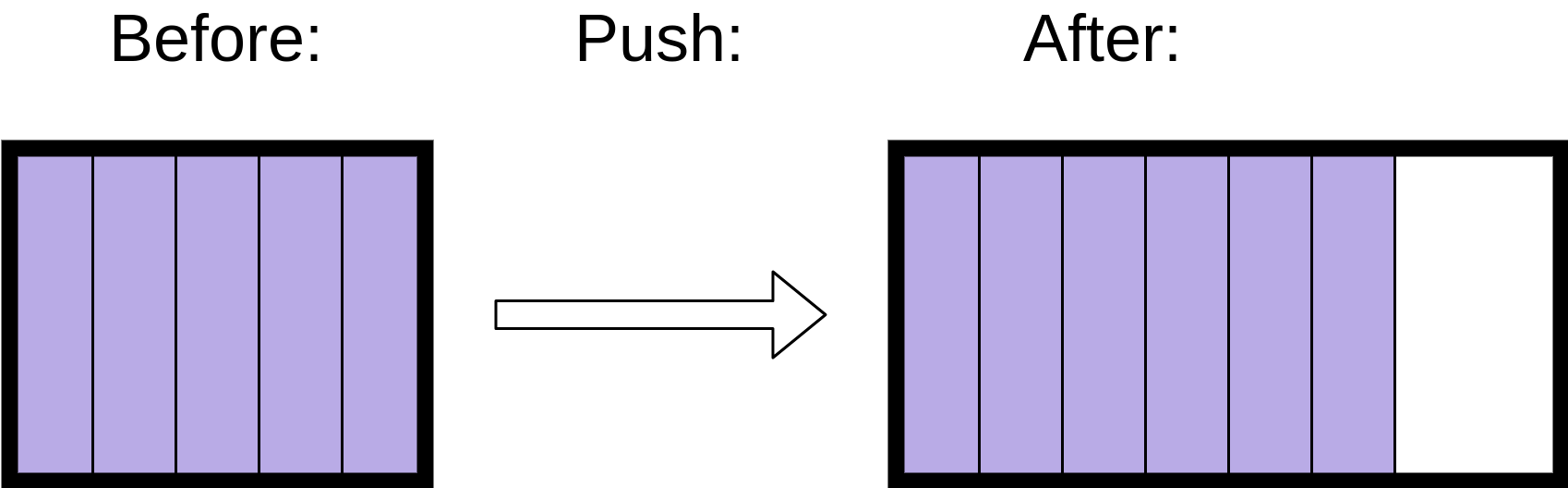
Непрерывное расположение памяти – причина, по которой списку может потребоваться больше времени для .append() одних объектов, чем других. Если блок смежной памяти заполнен, то ему потребуется получить другой блок, который может занять намного больше времени, чем обычный .append():
deque, с другой стороны, основан на двусвязном списке. В структуре связанного списка каждая запись хранится в своем собственном блоке памяти и имеет ссылку на следующую запись в списке.
Дважды связанный список точно такой же, за исключением того, что каждая запись имеет ссылки как на предыдущую, так и на следующую запись в списке. Это позволяет вам легко добавлять узлы в любой конец списка.
Добавление новой записи в структуру связанного списка требует только установки ссылки на новую запись так, чтобы она указывала на текущую вершину стека, а затем указывала вершину стека на новую запись:
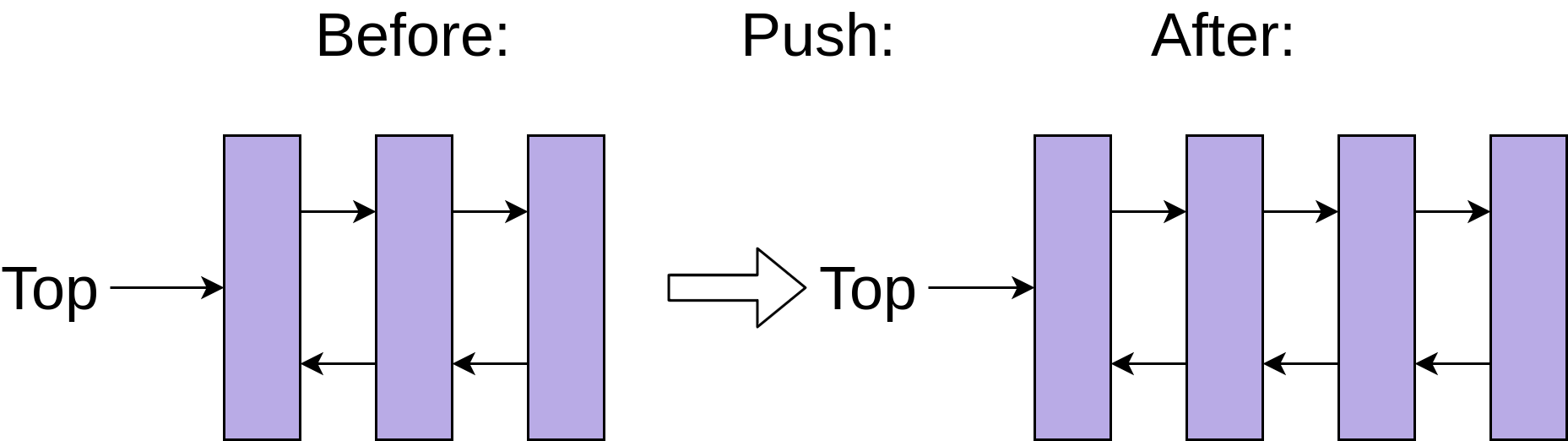
Однако это постоянное добавление и удаление записей в стеке сопряжено с компромиссом. Получение данных по индексу myDeque[3] медленнее, чем для списка, потому что Python должен пройти через каждый узел списка, чтобы добраться до третьего элемента.
К счастью, вы редко будете выполнять случайную индексацию или использовать срезы в стеке. Большинство операций над стеком будут push или pop.
Операции .append() и .pop() с постоянным временем делают deque отличным выбором для реализации стека Python, если ваш код не использует многопоточность.
Python стеки и многопоточность
Стеки Python могут быть полезны и в многопоточных программах.
Два варианта, которые вы видели до сих пор, list и deque, ведут себя по-разному, если в вашей программе есть потоки.
Начнем с более простого, запомните вы никогда не должны использовать list для какой-либо структуры данных, к которой могут обращаться несколько потоков. Список не является потокобезопасным.
Примечание. Если вам нужно освежить в памяти информацию о безопасности потоков и условиях гонки, ознакомьтесь с Введение в потоки в Python (An Intro to Threading in Python).
Однако, с deque немного иначе. Если вы прочтете документацию по deque, в ней будет четко указано, что обе операции .append() и .pop() являются атомарными, то есть они не будут прерваны другим потоком.
Так что если вы ограничитесь использованием только .append() и .pop(), то у вас не будет проблем с потоками.
Проблема использования deque в многопоточной среде заключается в том, что в этом классе есть и другие методы, которые специально не предназначены для атомарной работы и не являются поточно-ориентированными.
Таким образом, хотя можно создать потокобезопасный стек Python с использованием deque, это подвергает вас опасности тому, что кто-то в будущем злоупотребит им и вызовет условия гонки.
Хорошо, если вы работаете с потоками, вы не можете использовать list для стека и, вероятно, не захотите использовать deque для стека, так как же вы можно построить стек Python для многопоточной программы?
Ответ находится в модуле очереди, queue.LifoQueue. Помните, как вы узнали, что стеки работают по принципу «последний пришел / первый вышел»? Ну, вот что означает «Lifo» в LifoQueue.
В то время как интерфейс для list и deque похожи, LifoQueue использует .put() и .get() для добавления и удаления данных из стека:
>>> from queue import LifoQueue
>>> myStack = LifoQueue()
>>> myStack.put('a')
>>> myStack.put('b')
>>> myStack.put('c')
>>> myStack
<queue.LifoQueue object at 0x7f408885e2b0>
>>> myStack.get()
'c'
>>> myStack.get()
'b'
>>> myStack.get()
'a'
>>> # myStack.get() <--- waits forever
>>> myStack.get_nowait()
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/usr/lib/python3.7/queue.py", line 198, in get_nowait
return self.get(block=False)
File "/usr/lib/python3.7/queue.py", line 167, in get
raise Empty
_queue.Empty
В отличие от deque, LifoQueue разработан так, чтобы быть полностью поточно-ориентированным. Все его методы безопасны для использования в многопоточной среде. Он также добавляет дополнительные тайм-ауты для своих операций, которые часто могут быть обязательной функцией в многопоточных программах.
Однако такая полная безопасность потоков обходится дорого. Чтобы достичь этой безопасности, LifoQueue должен выполнять немного больше работы над каждой операцией, а это значит, что это займет немного больше времени.
Зачастую это небольшое замедление не влияет на общую скорость вашей программы, но если вы измерите свою производительность и обнаружите, что ваши операции со стеком являются узким местом, тогда стоит осторожно перейти на deque.
Стеки Python: какую реализацию следует использовать?
В общем случае, вы должны использовать deque, если вы не используете многопоточность. Если вы используете многопоточность, то вам следует использовать LifoQueue.
Список может быть прост, но его следует избегать, потому что он может иметь проблемы с перераспределением памяти. Интерфейсы для deque и list идентичны, и deque не имеет этих проблем, что делает deque лучшим выбором для вашего непоточного стека Python.
Заключение
Теперь вы знаете, что такое стек, и видели ситуации, когда их можно использовать в реальных программах. Мы оценили три различных варианта реализации стеков и увидели, что deque – отличный выбор для непоточных программ. Если вы реализуете стек в среде многопоточности, то, вероятно, будет хорошей идеей использовать LifoQueue.
Теперь вы можете:
- Распознать, когда стек будет хорошей структурой данных
- Выбрать, какая реализация лучше подойдет для вашей проблемы
Оригинальная статья: Jim Anderson How to Implement a Python Stack
Хороший перевод хорошей статьи
Хорошая статья, браво, автор!
“Это руководство предназначено для питонистов, которые хорошо разбираются в сценариях, знают, что такое списки и как их использовать” – обратите на это внимание перед прочтением и не тратьте свое время! Очень интересно, но мне ничего не понятно.
Прям прекрасная статья, спасибо:)